
「ロト6 当せん数字予測アプリ」
「ロト6 当せん数字予測アプリ」 (以下、本アプリ) は、ロト6 の当せん数字の抽せんに用いられる セット球 のデータをもとに、次回の当せん数字を予測するためのヒントを提供するアプリです。
...が、実用性はほとんどありません (笑)。
サイト主は、本アプリと同じ方法で、数年にわたりロト6 の当せん数字を予測していますが、これまでに 5 等(1000 円)を数回獲得したことがある程度です。
本アプリは、あくまでも Python で開発されたアプリのデモ・サンプル作品としてお試しください。
ちなみに本アプリでは、過去の ロト6 の当せん数字データを CSV ファイルに出力することもできます。
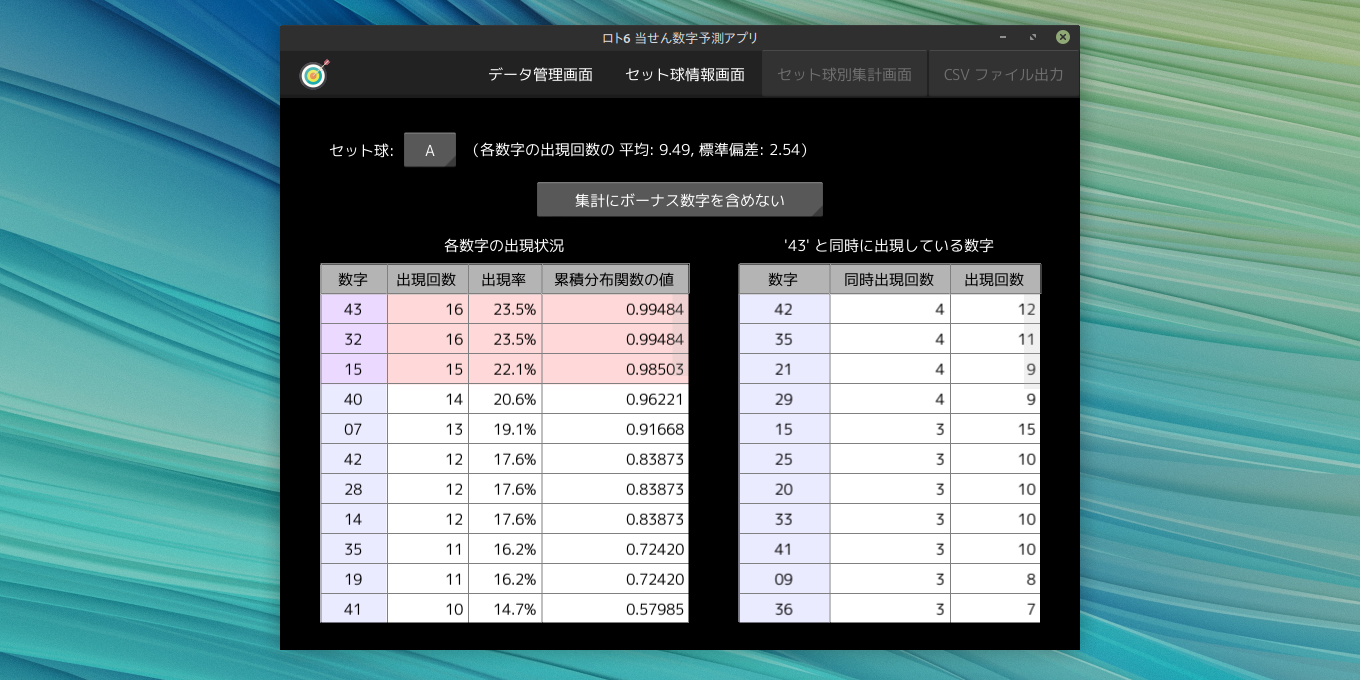

アプリについて
本アプリは、プログラミング言語 Python で開発したデスクトップアプリで、 GUI に Kivy(キヴィ)ライブラリ、 データの管理・集計に Polars(ポーラース)ライブラリを利用しています。
本アプリには、Windows 版と macOS 版があります。
いずれも、各 OS 上で単体で動作する形式(exe や app)にビルドされているので、Python の動作環境のインストールは不要です。
本アプリの macOS 版は Apple シリコン 搭載 Mac のみ対応しています。
Intel プロセッサ 搭載 Mac では動作しません。
確認方法は こちら。
アプリのダウンロード
以下のリンクから、本アプリとその説明書をダウンロードできます。
ソースコードのダウンロード
以下のリンクから、本アプリのソースコードをダウンロードできます。
Python のプロジェクト・パッケージ管理に uv をご利用の場合は、 "uv sync" コマンドだけで環境を構築できます。
ソースコードをご利用の際は、 ライセンス の項目をお読みください。
また、ソースコードは Python 3.13、および添付の requirements_*.txt に記載された環境以外での動作確認は行っておりません。
ご利用は自己責任でお願いいたします。
更新履歴
- v1.0.2.2 [2026/03/15]
-
- メイン画面の「データを取得」ボタンを「ウェブからデータ取得」に変更した。
- 各 Python ライブラリをアップデートした。
- v1.0.2.1 [2025/12/15]
-
- コードの見直しを行った。
- 各 Python ライブラリをアップデートした。
- v1.0.2.0 [2025/10/01]
-
- macOS 版の「ファイル出力」ダイアログボックスで、日本語のファイル名を入力する際の不具合を修正した。
- Python を Version 3.13 に更新した。
- 各 Python ライブラリをアップデートした。
- v1.0.1.0 [2025/06/26]
-
- datagrid を独立したパッケージに変更した。
- MIT ライセンス全文の参照先 URL を変更した。
- v1.0.0.0 [2025/06/18]
- 初版リリース。
ライセンス
「ロト6 当せん数字予測アプリ」(以下 本ソフトウェア)の著作権は、 開発者である 筒井敏文 が保有します。
本ソフトウェアのバイナリファイル、およびソースコードは
MIT ライセンス
の下で配布します。
本ソフトウェアのバイナリファイル、およびソースコードの改変や再配布は自由に行うことができます。
ただし再配布の際には必ず、添付の "LICENSE.TXT" ファイルを配布物にも添付するか、
または配布物のわかりやすい場所に以下の 3 行を記載してください。
Copyright (c) 2025 toshifumi tsutsui
Released under the MIT license
https://wpandora8.net/the_mit_license.html
なお、著作権者は、本ソフトウェアのバイナリファイル、およびソースコードに起因または関連し、 あるいはバイナリファイルおよびソースコードの使用またはその他の扱いによって生じる一切の請求、 損害、その他の義務について何らの責任も負わないものとします。
